Benchmarking Envoy Proxy, HAProxy, and NGINX Performance on Kubernetes


Edge Proxies in Kubernetes
Benchmarking latency on Kubernetes
Test Setup
Results: 100 RPS
Results: 500 RPS
Results: 1000 RPS
Summary
Measuring proxy latency in an elastic environment
In a typical Kubernetes deployment, all traffic to Kubernetes services flows through an ingress. The ingress proxies traffic from the Internet to the backend services. As such, the ingress is on your critical path for performance. There are a wide variety of ways to benchmark and measure performance.
Perhaps the most common way of measuring proxy performance is raw throughput. In this type of testing, increasing amounts of traffic is sent through the proxy, and the maximum amount of traffic that a proxy can process is measured. A typical measurement for this will measure performance in Requests Per Second (RPS).
In reality, however, most organizations are unlikely to push the throughput limits of any modern proxy. Moreover, throughput scales linearly -- when a proxy is maxed out on throughput, a second instance can be deployed to effectively double the throughput.
This article explores a different type of performance: latency. Each request through a proxy introduces a small amount of latency as the proxy parses a request and routes the request to the appropriate destination. Unlike throughput, latency cannot be improved by simply scaling out the number of proxies. And, critically, latency has a material impact on your key business metrics.
Edge Proxies in Kubernetes
Arguably the three most popular L7 proxies today are Envoy Proxy, HAProxy, and NGINX. In Kubernetes, these proxies are typically configured via a control plane instead of deployed directly. In this article, three popular open source control plane / proxy combinations are tested on Kubernetes:
- ingress-nginx, the most common ingress for Kubernetes, built on NGINX. We used , which is based on OpenResty 1.15.8, which in turn is based on NGINX 1.15.8.
nginx-ingress-controller:0.25.0 - The HAProxy ingress controller (https://github.com/jcmoraisjr/haproxy-ingress), version , which is based on 1.8.21. We tried to use the official HAProxy ingress controller. However, at the time of testing, the official controller exposed only 8 configuration options, which made it impossible to use for the benchmark. More recently this has expanded into 25 configuration options.
0.7.3 - Edge Stack, which is built on Envoy Proxy.
Benchmarking latency on Kubernetes
Containerized environments are elastic and ephemeral. Containers are created and destroyed as utilization changes. New versions of containerized microservices are deployed, causing new routes to be registered. Developers may want to adjust timeouts, rate limits, and other configuration parameters based on real-world metrics data.
In our benchmark, we send a steady stream of HTTP/1.1 requests over TLS through the edge proxy to a backend service (https://github.com/hashicorp/http-echo) running on three pods. The edge proxy is configured to do TLS termination. We then scale up the backend service to four pods and then scale it back down to three pods every thirty seconds, sampling latency during this process. We cycle through this pattern three times. We then simulate some routing configuration changes by making three additional changes at thirty second intervals:
- CORS headers
- Adding a custom response header
- Rewriting the request path
We then revert back to the base configuration. We measure latency for 10% of the requests, and plot each of these latencies individually on the graphs.
Test Setup
All tests were run in Google Kubernetes Engine on
n1-standard-1kube-proxykube-proxyIn general, the default configurations for all ingresses were used, with two exceptions:
- With NGINX, we increased from the default 100 to 2147483647 to enable connection reuse
keep-alive-requests - With Ambassador Edge Stack, endpoint routing was utilized to bypass . (Note that we didn't need to change this for NGINX and HAProxy, because they use endpoint routing by default.)
kube-proxy
Multiple test runs were conducted by multiple engineers to ensure test consistency.
Results: 100 RPS
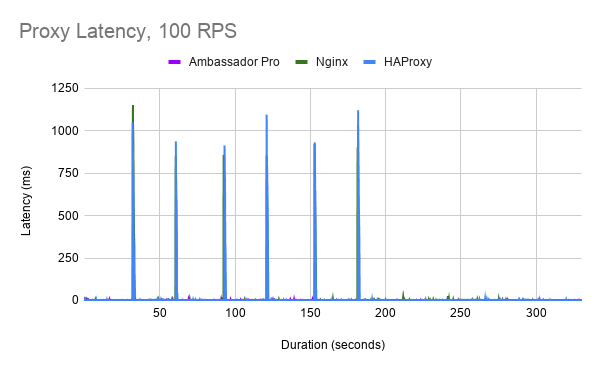
At a 100 request per second load, requests to HAProxy when the backend service is scaling up or down spike to approximately 1000ms. The duration of these spikes is approximately 900ms.

NGINX has slightly better performance than HAProxy, with latency spikes around 750ms (except for the first scale up operation). These latency spikes are approximately 900ms in duration.

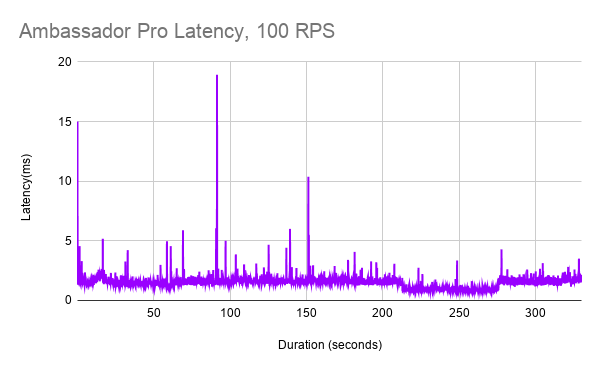
With Edge Stack API Gateway and Envoy Proxy, we see significantly better performance. Note the different Y axis in the graph here. No clear pattern of latency spikes occur other than a 25ms startup latency spike. Most latency is below 5ms.
To view these numbers all in context, we've overlaid all latency numbers on a single graph with a common scale:
Results: 500 RPS
At 500 RPS, we start to see larger latency spikes for HAProxy that increase in both duration and latency. Latency spikes to as long as 10 seconds, and these latency spikes can last a few seconds.
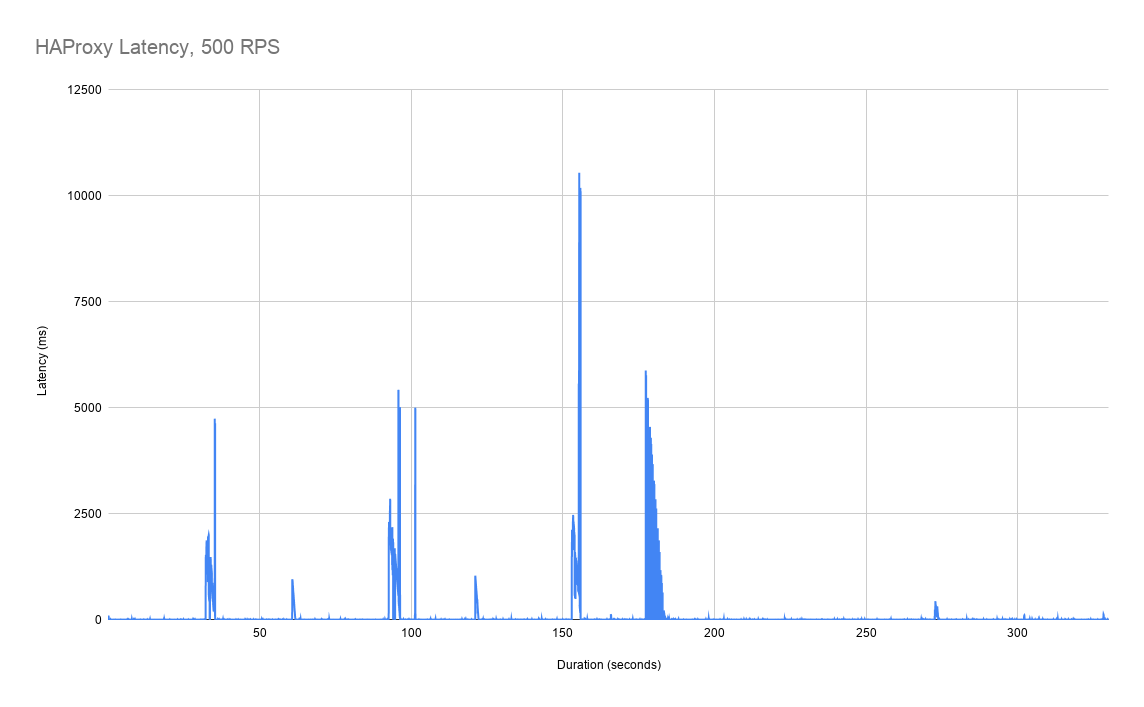
NGINX performs significantly better than HAProxy in this scenario, with latency spikes that are consistent around 1 second, with similar duration as in the 100 RPS case.

With Ambassador Edge Stack/Envoy, latency generally remains below 10ms. There is also a large unexplained latency spike towards the end of the test of approximately 200ms. (We think this is something related to our testing, but are doing further investigation.)

Again, we can view all these numbers in context on a combined chart:

Results: 1000 RPS
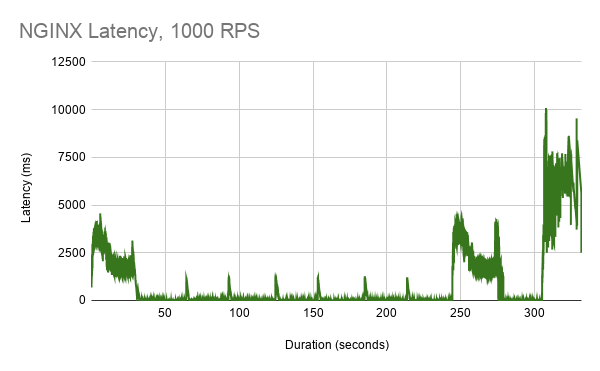
Finally, we tested the proxies at 1000 RPS. HAProxy latency spikes get even worse, with some requests taking as long as 25 seconds.
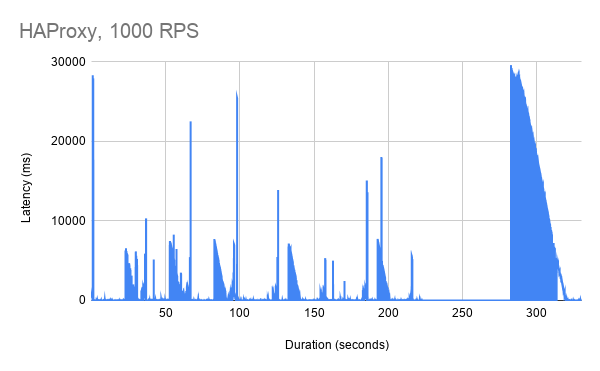
NGINX outperforms HAProxy by a substantial margin, although latency still spikes when pods are scaled up and down. Interestingly, we see a substantial latency spike when we adjust the route configuration, when we previously had not observed any noticeable latency.
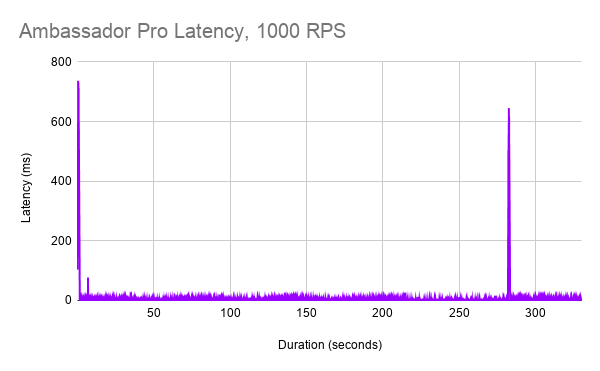
With Ambassador Edge Stack/Envoy, we see a brief startup latency spike and another anomalous latency spike. Latency across the board remains excellent and is generally below 10ms.
Again, we can view all these numbers in context on a combined chart:

Summary
Measuring response latency in an elastic environment, under load, is a critical but often-overlooked aspect of ingress performance. As organizations deploy more workloads on Kubernetes, ensuring that the ingress solution continues to provide low response latency is an important consideration for optimizing the end user experience.